Advances in computer vision, and chasing the long tail

Face Recognition Software Recognizes Animals Now Too - Terry Kimura

Following a Person - Image Detection, Color Association and Kalman Filters - Vislab
Note
This text was produced for a seminar-based class in which students were encouraged to attend a series of guest lectures and submit a short paper on one of them.
This post is in response to “Understanding visual appearances in the long tail” by Deva Ramanan, Associate Professor at the Robotics Institute at Carnegie Mellon University.
I thought it could be worth posting, and may continue to post notes on other seminars as interest takes me deeper into various topics.
Images were scoured from the web for this article, with the requirement of being under Creative Commons licenses or the public domain.
Introduction
Computer vision has developed into a high-profile sub-domain of artificial intelligence, benefiting from a number of industry-ready applications and sustained interest from the global community. As learning techniques and algorithms have advanced, we have also gained a vast amount of readily available training data from the Internet. Every day, hundreds of millions of photographs and videos are added to the public domain.
While the rich source of material has been a boon for learning algorithms and networks, it has not detracted from the problem of skew in training data. Samples such as photographs of people are frequently biased towards a limited set of patterns and characteristics, while a wide distribution of possible patterns and poses may be found only rarely.
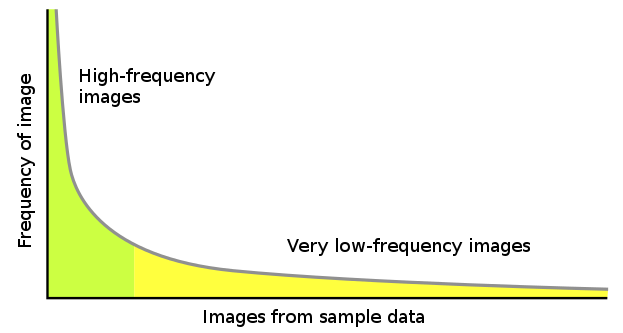
The long tail problem in computer vision. The majority of all possible patterns are often rare or missing from sample data, which typically contains many variations on a small selection of patterns.
This skew, often referred to as “the long tail problem”, is a general phenomenon in artificial intelligence, and several strategies have been proposed for limiting its influence. Common methods include careful construction of learning algorithms to balance the weights assigned to various patterns, attempting to collect as wide a set of edge case samples as possible, and breaking down images into smaller components to better capture the relation between those components.
Another, complementary, strategy that Deva Ramanan and others have proposed, is to manipulate existing samples to synthesize new training data. By fragmenting and transforming known templates of objects, many new images may be added to the set of templates, thus reducing the long tail of rare events that would otherwise be missed.
In this paper we review some of the techniques presented in Deva Ramanan’s talk, their underlying assumptions, and a few of their benefits and challenges. We summarize some of the properties of common strategies for improving pattern recognition of complex subjects, as well as some of the computational challenges inherent in this problem space and how they may be partly mitigated or front-loaded to allow business applications to approach liveness.
Refining templates for pattern recognition
Many modern pattern recognition systems use generic models or templates for target objects and features, which are refined through testing against a range of positive and negative samples. These templates may be visualized as rough sketches of key features of the target object, such as the general form of a person with markings in areas where limbs may be expected.
Templates can be evaluated by the frequency in which they accurately characterize images, and penalized by the number of times they inaccurately mark negative samples as matches. By building up a library of high-scoring templates, a diverse range of images can be accurately characterized or scanned to identify specific features.

"Real-Time Adaptive 3D Face Tracking and Eye Gaze Estimation" - Vicomtech-IK4 demonstrating 3D deformable face models and adaptive facial texture learning.
This approach has been extended through learning algorithms that automate much of the process, and which develop dynamic templates that can be adjusted over time as more samples are processed.
The problem with this type of approach is that there is a continuous need to add more dissimilar templates as previous templates may be irrelevant to new or rare types of samples. There are wide ranges of body types and postures possible, making it difficult to generate a template that will cover every type and age of person standing, sitting, jumping or lying down. Any template that is generic enough to do so will also match against a wide variety of negative samples such as furniture and foliage. More discerning, and more specific templates than this are needed.
A more compelling way to consolidate templates is to produce a weighted template for common subcategories of positive samples, which can resemble a sort of heat map. The resulting templates may miss a large number of positive samples that do not match their subcategory, however, they are also less likely to report false positives. Weighted templates can limit the number of templates required for common categories of samples. However, they do not address the problem of how to match against rare categories of samples.
Underlying assumptions behind template refinement:
-
There is a sufficient source of sample data for template evaluations to be generalizable.
- This is no longer as much of an issue as it may have once been, as content sharing platforms such as Flickr provide a ready source of tagged photographs.
-
It is easy to evaluate the accuracy of a given template.
- Once a sufficiently large set of positive and negative samples have been assembled, a variety of scoring methods may be used. It isn’t so clear how individual templates should be scored, because any given template will fail to match any number of samples from other categories. However, each template should avoid false positives. The naive conclusion would be that every template should be as specific as possible.
- Merging similar templates into weighted templates mitigates this problem, and reduces it to a matter of setting a threshold for acceptable frequency of correct matches or rejections.
- It may be possible to focus on the set of templates rather than the individual template, so long as each template does not yield too many false positives. In this case, possible heuristics could include requiring that adjustments or additions to the set of templates improve the overall frequency of correct matches and rejections.
-
It is easy to generate new templates to match against sample data.
- A simple concept would be to add a new template for every positive sample not covered by the current set of templates. If this approach was taken, then a very large number of accurate templates could be built up, however this also suggests a very large amount of computation required for matching or rejecting individual images.
- Evaluating an image against a set of templates is highly parallelizable, so while we want to take care not to require exponentially larger numbers of templates for exponentially larger populations, a few thousand weighted templates would not be unmanageable. To achieve liveness, we would expect to want to prune to a smaller set of weighted templates at the cost of slightly decreased accuracy.
Part-based templates
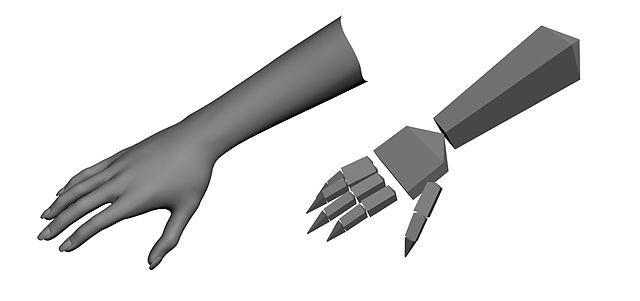
"Typical skeletal hand used by gesture recognition software" - Razvan
One way to deal with variations in object configurations and body poses is to divide an object into compositional parts, and match for individual parts with the added requirement that the parts be connected and relatively positioned in the expected way. This “loosening of the joints”, so to speak, leads to a more complex algorithmic model, but also to a more flexible type of template that is more broadly applicable than static templates can be.
One of the interesting caveats of this suggestion is that it gives no direction on how to choose the components. In general, it is difficult to guess what components should make up a given object. However, for specific cases, we can use domain knowledge to make educated guesses, and test how different components affect the scores of our templates.
We are familiar with the specific body structure of an adult or child, and it then becomes a question of how fine-grained we wish to subdivide the human body. Simple templates could be composed purely of upright rectangles, and be comprised of as few as three to five rectangles for the general body and the limbs. If more detail is required, rotated or non-standard shapes could be allowed, even going to the detail of features such as eyes and fingers.
The more small components we allow for, the more computational power required to match an image, so the intended use of the system and the nature of the target object can make a large difference to our focus. For some systems it may be sufficient to just have a mannequin-styled model, or, if minute facial expressions must be reflected, more work may be put into generating fine-grained models. In addition, some applications such as facial recognition systems may have a large degree of domain knowledge they can start from to quickly generate templates for new faces, leading to less work required to refine each person’s template.
Underlying assumptions behind part-based templates:
-
There is a well-defined method for determining what components make up a given object.
- This is far from clear, and we may often avoid this problem by starting from a foundation of domain knowledge about our subject. This is often the case for business applications, particularly with regards to surveillance.
-
There is a well-defined method for determining the coarseness of our component sub-templates.
- This was not discussed in much detail and was mainly alluded to in the way of comparing variations of rectangular sub-templates per body part versus larger sub-templates that cover contiguous segments of the subject. It remains an interesting question as to how much we can automate the trial and refinement of various template break-downs.
- The generation and tuning of accurate template sets is already expensive computationally, without adding another level of complexity. It may be much easier and more practical to choose a coarseness level to start with and compare results against a few options of block vs skeletal patches, however it will be interesting to see how different research groups approach this problem.
-
There is a well-defined method for evaluating an image against a set of loosely connected sub-templates.
- This is less of a theoretical problem than a challenging optimization exercise, as there are potentially an exponentially larger number of possible configurations that should be tested before rejecting an image.
Synthesizing new data and templates
One final technique from the presentation that we will discuss is synthesis of new data and templates from what we already have. Many of the earlier discussed techniques do not address the problem of determining how to handle rare or unknown cases, and require that we know whether the image is a positive or negative match in advance. This is only reasonable during the initial training phase, when we are working within the confines of clearly categorized samples to train our system. Once we are ready to deploy our system, we must be able to adapt to new data that has not yet been categorized. We cannot cover all possible subcategories of data in general, but we can seek ways to sharply increase the percentage of possible subcategories that we are able to work with.
If we are lacking in training data, one technique that we can try is to adjust and transform our existing positive and negative samples into a number of novel configurations. This works best when we have a large amount of domain knowledge embedded into our transformation algorithm. For example, for a person’s face, it would be reasonable to produce mirror images, extend the length of someone’s nose, or stretch the overall face, however we would not want to move someone’s mouth to their eyes.
Synthesizing new templates combines the experience from previous methods by taking existing templates and transforming and rotating each template or sub-template to produce a number of new configurations. Because the original templates have already evaluated well against positive and negative samples, the transformed versions can also be considered to be high-quality. In contrast to earlier templates, these templates are generated in expectation that they are accurate rather than by closely matching positive samples, and the expectation is that they will be able to match well against new sample data that does not conform to the original templates.
Part-based templates are especially useful for this transformation process, as many more realistic manipulations can be performed. This yields a much more varied set of positive templates than could otherwise have been achieved. Thus, once a set of templates has been generated through training against pre-categorized samples, data synthesis can be used to multiply the size and flexibility of the template set against new sample data.
Underlying assumptions:
-
We know which components can be transformed, and to what degree.
- It is important to note that not all possible transformations may be reasonable, and many possible transformations may yield sub-par or misleading templates.
- This is much easier to work on when we have extensive knowledge of the subject at hand, as with the human body. For a human template, we can limit the degree of rotation of given body parts, and similarly define limits to how far components can be transformed.
-
Breaking down and reconfiguring the components of templates that closely match many known samples will result in still-accurate templates.
- This can be justified when we are able to limit reconfiguration to the extent that is possible and natural for the subject, however, this may again require an amount of domain knowledge about the subject.
- It is important to note that too many extensive transformations may result in a larger number of false positives against inanimate objects and non-target subjects that are now matched by the contorted templates.
-
The templates generated through reconfiguring existing templates will result in correctly matching against a significant number of variations that we have not yet seen.
- This is the essential assumption that, if true, gives value to synthesizing new templates.
- This assumption is more likely to hold in cases where we are able to obtain a large variety of initial samples to generate templates for, and less likely to hold when our initial sample is roughly homogeneous.
Synthesizing new data and templates can be very computationally expensive, and may not always be appropriate. It is difficult to generalize to areas where we are unsure of what transformations are possible. However, when we have enough variety in our initial sample and have knowledge over the extent of likely possible transformations, reconfiguring part-based templates may be a useful technique for significantly increasing the number of subcategories of samples that we will be able to categorize appropriately.
Note again that as we exponentially increase the number of disjoint templates to sweep across samples, we increase the amount of computational power required. We do not have an unlimited amount of computational power for routine tasks, so when we do apply these techniques we may want to use a limited but varied set of transformations. We can also merge similar templates into weighted templates to result in a flexible but limited-size set of templates for system deployment.
Concluding points
A number of techniques have been developed in computer vision for improving pattern recognition and categorization to the extent that it can be used for complex and malleable subjects. Many of these techniques are already being used for processing and analyzing images and video feeds, and even some problems that have been thought to be very theoretically challenging have become accessible by considering limited sub-problems and applying what domain knowledge is available.
As new techniques have been proposed and implemented, the Internet revolution and its now ubiquitous content-sharing platforms has significantly expanded the amount of data available to learning systems. While training periods can still be long and expensive, the variety of training data can result in more robust and flexible systems. Merging similar templates into weighted templates allows for categorization to remain accurate while sharply reducing the number of necessary scanning cycles, which allows more powerful recognition and categorization systems to perform at an improved rate.
The long tail problem continues to persist, and there will always be a wide distribution of rare configurations that are difficult to prepare for. However, even for areas where our training data only covers a small subset of possible configurations, there exist techniques for expanding our models beyond our initial samples.
Manipulating existing samples and part-based templates allows us access to a much wider range of possible configurations. This leads directly towards synthesis of new templates, which confirms and solidifies the utility of part-based templates in yielding a pattern recognition system that can adjust to a much wider variety of configurations. These manipulations must either be limited in scope, or require built-in knowledge of the subject to remain realistic and useful. If we do allow domain knowledge to be ingrained into the system, this may decrease the wider applicability of our system, but can yield much better results in a shorter period of time. This continues to be a practical tradeoff to make, especially for technologies intended for a specific industry.
Sources
Ramanan, Deva. “Understanding Visual Appearances in the Long Tail.” UBC Department of Computer Science Distinguished Lecture Series. UBC, Vancouver. 24 Sept. 2015. Lecture.
Images
Following a Person: Image Detection, Color Association and Kalman Filters. Digital image. YouTube. Vislab Lisboa, 4 Mar. 2016. Web. 6 June 2016. https://i.ytimg.com/vi/L6bilpwjEf8/maxresdefault.jpg.
{kind=link}
Husky. Long tail.svg (Picture by Hay Kranen). Digital image. Wikimedia Commons. N.p., 10 Dec. 2006. Web. 6 June 2016. Used and modified under the Public Domain.
Kimura, Terry. Face Recognition Software Recognizes Animals Now Too. Digital image. Flickr. N.p., 29 Nov. 2010. Web. 6 June 2016. Used under Creative Commons Attribution-ShareAlike 2.0 Generic (CC BY-SA 2.0).
Razvan. Skeletal-hand.jpg. Digital image. Wikimedia Commons. N.p., 21 Mar. 2011. Used under Creative Commons Attribution-Share Alike 3.0 Unported.
Real-Time Adaptive 3D Face Tracking and Eye Gaze Estimation. Digital image. YouTube. Vicomtech-IK4, 11 Oct. 2012. Web. 6 June 2016.